【Excel】条件付き書式の使用例
条件付き書式は、セルの値に応じてフォントや背景色、罫線、表示形式等の書式を自動的に設定する機能です。あくまで書式設定ですので、入力値や計算結果の値をどう見せるかといった視覚的な表現を行う機能となります。計算面ではスピルや新関数の登場でこれまでできなかった自動集計が可能になってきました。一方、書式設定はどちらかというと手作業に依るところが多い印象があります。色を付けたり、線を引いたりするのは作成者の主観に依る/明確なルールがない場合が多いといったことはあると思います。とはいえ、繰り返し作成するようなものであれば、ルールはできていくもの(そうあるべき)ではないでしょうか。一定のルールがあればその条件によってある程度の書式設定を自動化することは可能です。ということで、今回は条件付き書式のいくつかの設定例を紹介したいと思います。
- 1. 指定の値を含むセルを書式設定
- 2. 指定の値を含むセルと同じ行を書式設定①
- 3. 指定の値を含むセルと同じ行を書式設定②複数条件、複数ルール
- 4. 指定の値を含むセルと同じ行を書式設定③日付の月が変わる行に罫線を引く
- 5. 指定の値を含むセルと同じ行を書式設定④小計、合計行_その1
- 6. 特定のセルの値によって表示形式を切り替える(表示単位の変更)
- 7. カラースケールを使った書式設定
1. 指定の値を含むセルを書式設定
まずは基本的な設定です。下図のような管理表で、F列のステータスが「要確認」の場合にそのセルの背景色を変更します。
条件付き書式を設定するには、設定したいセル範囲を選択した状態(今回はF4:F13)で、メニューバー(リボン)の「ホーム」タブから、「条件付き書式」→「新しいルール」を選択します。(条件付き書式の適用範囲は一度設定した後で、後述する「条件付き書式ルールの管理」から変更可能です)
ルールの種類の二つ目の「指定の値を含むセルだけを書式設定」を選択し、ルールの内容を設定します。「次のセルのみを書式設定」で、「セルの値」「次の値に等しい」を選択し、その右に「=”要確認”」と入力します。その後、右下の「書式」ボタンをクリックします。
セルの書式設定には、「表示形式」「フォント」「罫線」「塗りつぶし」の4つのタブがあり、複数の組合せの書式設定も可能です。今回は、「塗りつぶし」タブで背景色(黄色)を設定しOKをクリックします。
下のプレビューで設定した書式を確認したらOKをクリックします。
セルに条件付き書式が反映され、F5セルの背景色が黄色になりました。
設定した条件付き書式の確認
先ほど設定したF4:F13セルのいずれかを選択した状態で、メニューバーの「ホーム」タブから、「条件付き書式」→「ルールの管理」を選択します。 先ほど設定したルールが表示されます。「適用先」はここで変更が可能です。連続したセル範囲のみだけでなく、“,”で区切ることで複数の範囲に同じルールを設定することもできます。
先ほど設定したルールが表示されます。「適用先」はここで変更が可能です。連続したセル範囲のみだけでなく、“,”で区切ることで複数の範囲に同じルールを設定することもできます。
ここまで、「新規ルール」、「ルールの管理」をメニューバーから選択する方法で説明しましたが、ショートカットキー「 alt+O、D 」で直接「ルールの管理」を開くことも可能です。「ルールの管理」から「新規ルール」の作成、編集、削除が行えますので覚えておくと便利です。
•
2. 指定の値を含むセルと同じ行を書式設定①
先ほどと同じ表で、同じようにステータスが「要確認」であった場合、F列だけでなく、A~E列にも書式設定をする方法です。先ほどのルールではセルの値が指定値でなければ書式設定の対象とならないため、適用範囲をA~F列に広げたとしても書式の変更はF列のみとなります。今回のような場合は、ルールの種類で「数式を使用して、書式設定するセルを決定」を選択してルールを設定します。
最終的な適用先範囲はA4:F13としますが、まずはF4セルに対してのルール設定で考えます。「次の書式を満たす場合に値を書式設定」に次の数式を入力します。
=$F4="要確認"
ここで重要なポイントは、「F4」ではなく、「$F4」 と複合参照にしていることです。つまり、F列のみを固定し、行は相対参照にすることで、適用先範囲をA4:F13に拡大したときに、いずれの行であってもF列の値が「要確認」であればA~E列にも指定した書式が設定されます。絶対参照、相対参照、複合参照に慣れていないとなかなか理解が難しいかもしれません。
処理に戻ります。先ほどと同様に書式設定をしたらOKをクリックします。
ルールの管理で、適用先の範囲をA4~F13に変更してOKまたは適用をクリックすると、セルに反映されます。

3. 指定の値を含むセルと同じ行を書式設定②複数条件、複数ルール
次は少し複雑なルールを設定してみます。表のデータは先ほどものから一部のデータを変更したものです。
条件は、ステータス(F列)が「完了」でない、且つ、終了予定日(D列)が現在の日付+5日以内の行に書式を設定します。現在の日付は2025年7月25日の想定で、明示的にD1セルにTODAY関数を入力しています(今回の条件付き書式の設定には関係しません)。下図の通り、以下数式を設定します。(下図は既に設定後の状態です)
=AND($F4<>”完了”,$D4<=TODAY()+5)
AND関数で複数の条件を設定します。複合参照は前項と同じ考え方で、F4が「完了」でない、且つ、D4が現在日付+5日以内(=2025/7/30以前)で書ぬ式が設定されます。
適用先はA4:F13とします。
複数の条件付き書式を設定することも可能です。先ほど設定したものに追加で新しいルールを設定してみます。ステータスが「完了」の行は背景色をグレーにする場合は下図の通りとなります。
ルールの管理は2つのルールが設定された状態になります。
4. 指定の値を含むセルと同じ行を書式設定③日付の月が変わる行に罫線を引く
(ここからは画像は簡便的にルールの管理の部分のみ表示します。)
日付順の複数データで月ごとに罫線を引きたい場合です。A列の日付のどの行で月が変わるかがわかればよいので、下図の通りMONTH関数を使って現在の行(A4)と次の行(A5)の月が一致するかを判定します。
5. 指定の値を含むセルと同じ行を書式設定④小計、合計行_その1
下図のように小計・合計行に書式設定します。ここは二つの例を紹介します。
まずは単純にC列の値が「小計」か「合計」の場合を条件にしました。数式はOR関数を使っていずれかに該当する場合としています。
次のケースは、D列の小計・合計が数式によって計算されていることを前提として設定したものです。ISFORMULA関数で数式かどうかを判定して該当する場合に書式を設定しています。この場合、C列に小計・合計の文字列がなくても判定できますが、D列がすべて文字列の場合や、すべて数式の場合は使えません。
6. 特定のセルの値によって表示形式を切り替える(表示単位の変更)
次はこれまでと少し趣向が変わったものです。下図のような円単位で入力されたデータを使います。A4セルに「単位:円」と文字列が入力されていますが、このセルを千円単位、百万円単位に変更することによって、データの金額の表示単位も連動して変更されるようにします。
まず、事前準備としてA4セルに対して「データの入力規則」を設定して、ドロップダウンで文字列を、単位:円、単位:千円、単位:百万円 のいずれかに切り替えられるようにしておきます。
次に条件付き書式を設定していきますが、デフォルトは円単位ですので、千円単位と百万円単位の二つを設定します。
まずは千円単位からです。設定する数式は次の通りです。
=$A$4=”単位:千円”
注意していただきたいのは今回はA4セル単独の値によって各適用先範囲の書式を変更するため、絶対参照で$A$4としているところです。
続いて「書式」の設定をします。
今回は「表示形式」タブでユーザー定義を選択して、種類に以下を入力します。
#,##0,;-#,##0,
数値のカンマ区切りの表示形式 #,##0 に続けて「,」(カンマ)をひとつ入力することで千円単位の表示形式となります。小数点以下を表示したい場合は、#,##0.0, のように入力します。また、表示形式の中を「;」で区切っていますが、左側が数値が正数の場合、;の右側が数値が負数の場合の設定になります。

百万円単位についても同様に設定します。
表示形式は、#,##0,,;-#,##0,,
です。百万円単位の場合、千円単位のときの設定の0のあとのカンマをさらに一つ追加して二つにします。

A4セルの値を切り替えると下図のように表示単位が連動して切り替わります。ただし、これはあくまで表示が変わっているだけでセルの中の数値自体はいずれも円単位のままですのでセルの数値を転用する場合等は注意が必要です。
7. カラースケールを使った書式設定
最後にカラースケールを使った書式設定の例を二つ紹介します。
選択した範囲に設定された最大値と最小値の中でグラデーションをつけて背景色を設定したい場合にカラースケールを使います。
まず一つ目の例です。下図のような表で進捗率の高いセルから順に濃い色を付けたい場合です。
新規ルールから書式ルールの編集の「セルの値に基づいてすべてのセルを書式設定」で、書式スタイル「2色スケール」を選択。
最小値| 種類:パーセント 値:0 色:白を選択(もとの背景色に合わせています)
最大値| 種類:パーセント 値:100 色:任意の色を選択

下図のように設定されます。
二つ目の例は、下図のようにマイナス金額を含んだ増減値に対して、増減額の大きなセルをカラースケールで明示したい場合です。
この場合は、書式スタイルで「3色スケール」を選択します。
最小値| 種類:数式 値:=MIN(対象のセル範囲) 色:任意の色を選択
中間値| 種類:数値 値:0 色:白を選択(もとの背景色に合わせています)
最大値| 種類:数式 値:=MAX(対象のセル範囲) 色:任意の色を選択
※最小値と最大値の色は同じ色を選択

下図の通り、増減の中の最大値と最小値を基準にカラースケールが設定されます。
【Excel】ランダムデータの作成例
列ごとに指定した数値の範囲または値(文字列)のリストから、任意の行数のランダムなデータを作成する例です。一度このような形で作っておくと再利用も可能です。
①下図のようなシートを用意します。今回、作成する列は「日付」「部門」「商品」「金額」の4列とします。A~E列に作成する条件を設定し、H~K列の2行目に数式を入力してランダムデータを作成します。
②作成行数(B1)は作成するランダムデータの行数を入力します。
③次に数値の範囲で指定する列の最小値と最大値を設定します。今回の例の場合は「日付」と「金額」をその対象にしています。「日付」は年月日の表示としていますが、中身はシリアル値ですので数値扱いとします。
④「部門」と「商品」は文字列のリストを設定して、その中からランダムデータを作成しますので、C8以下、D8以下にそれぞれ文字列を入力します。数の制限はなく(8行目以下のセルすべて)、他ブックからのコピー&ペーストでも大丈夫です。
⑤H2セルに以下数式を入力します。
=IF(AND(B4:B5<>""),
RANDARRAY($B$1,1,B4,B5,TRUE),
INDEX(DROP(B:B,7),RANDARRAY($B$1,1,1,COUNTA(DROP(B:B,7)),TRUE),1))

⑥H2セルの数式をコピーして、I2、J2、K2セルに貼付けます。作業はこれで完了です。
⑦数式の中身について以下説明します。
まずは、H2セルの数式です。数式はわかりやすいようにIF関数の引数ごとに改行しています。IF関数の論理式は、AND(B4:B5<>"") です。つまり、「B4、B5セルがどちらも空白ではないか」です。B4、B5いずれも値が入力されていますのでTRUEとなり、2行目の数式が実行されます。
その2行目は、RANDARRAY関数です。この関数は引数に[行]、[列]、[最小値]、[最大値]、[整数]を設定して乱数の配列を返します。セルに入力した情報を参照しながら引数を入れていきます。第1引数[行]は作成したい行数ですので、B2セルを参照します。この行数の参照は他の列の数式でも固定となるため絶対参照 $B$1を指定します。
第2引数[列]は1列固定となりるため、1 を入力。第3[最小値]、第4[最大値]はB4、B5セルを参照します。最後の第6[整数]はTRUEの場合は整数値、FALSEの場合は少数値となりますが、ここではTRUEとします。これで設定した条件に合った日付の配列が作成されます。
⑧続いて、I2セルの数式を説明します。IF関数の論理式 AND(C4:C5<>"") の結果はFALSEとなりますので、3行目の数式が実行されます。流れとしては、C8以下に入力されている文字列の位置の乱数配列をRANDARRAY関数で作成し、INDEX関数でそれらの位置に対応する文字列を返します。
内側のRANDARRAY関数から説明します。第1引数[行]の$B$1、第2引数[列]の 1 は先ほどと同じ考え方です。第3引数[最小値]は、C8以下に入力する文字列は最低1つは必要なわけですから 1 で固定とします。第4引数[最大値]は、C8セル以下に入力された文字列の個数とします。C1~C7は対象外とするため、DROP関数で先頭の7行を削除します。第5引数は先ほどと同じくTRUE(整数)とします。
次に外側のINDEX関数です。第1引数の[配列]は、先ほどと同じく DROP(C:C,7) とします。第2引数の[行番号]は、前段で説明したRANDARRAY関数による文字列の位置の配列です。第3引数[列番号]は1で固定となります。
これで、任意の文字列のリストからランダムなデータを作成することができました。
A〜E列の入力を変更すると数式の結果に反映されます。
【Excel】ブール値(TRUE/FALSE)
「ブール値(Boolean値)とは、真(True)か偽(False)の2つの値のいずれかを表す値のことです。これは、論理演算や条件分岐などでよく使われる基本的なデータ型です。」
Excelの計算においても論理計算の基本になるところで、最近個人的にはスピルで配列を扱う際に意識することが増えている気がします。
今回はこのブール値について、考えてみたいと思います。
1.基本
① まず、ワークシート上でブール値を返す数式を入力してみます。セルに =2=2 と入力すると、TRUE が返ります。次に =2=3 と入力すると、FALSE が返ります。これがブール値です。
② ブール値は数値で表すこともできます。先に入力したセルを参照して、1を乗じると下図のようにTRUEは1、FALSEは0 となります。
③ また、数式の中で直接 TRUE、FALSE を使うこともできます。下図は=TRUE , =FALSE と入力した結果です。ただし、頭に"="を入れずにTRUEとだけ入力した場合は文字列として認識されます。(見た目は同じです)
2.配列の値が条件に合致するかを判定
④ ここからは、下図のサンプルデータを用いて、いくつかの例をみていきたいと思います。基本的に数式は範囲に対して計算を行い、スピルした結果を返すようにします。
⑤ 「金額」が100以上かどうかを判定する数式を入れます。=C3:C9>=100 と入力すると、100以上はTRUE、100未満はFALSEが返ります。
⑥ ここで、IF関数を考えてみたいと思います。IF関数の書式、=IF(論理式、[値が真の場合],[値が偽の場合]) を見てもわかる通り、IF関数とブール値は非常に深い関係にあります。
先ほどの数式は「金額」が100以上かどうかで、TRUEかFALSEを返すのみでした。これにIF関数を加えて、100以上の場合は、”100以上”を、100未満の場合は”100未満”を返す数式に変えると下図のようになります。
⑦ 次は「区分」が”B”であるかどうかを判定する場合。
⑧ 次は「日付」が最新月であるかどうか。これを判定するにはどうしたらよいでしょうか。式を分割して考えてみます。
①まず、日付から月を返すためにMONTH関数を使います。=MONTH(A3:A9)
②次に①で算出した月の内、最大値をMAX関数で返します。=MONTH(MAX(A13:A19))
③①と②を合わせて最新月かどうかを判定します。=MONTH(A23:A29)=MONTH(MAX(A23:A29))
3.FILTER関数で活用する
⑨ ここまで3パターンの判定をみてきました。これらをFILTER関数の第2引数に使うことで、対象の配列を条件に合致するものだけに絞り込んで表示することができます。
FILTER関数の書式は、=FILTER(配列,含む,[空の場合]) です。下図E、F列は前項までの結果で、G~I列にFILTER関数の式と結果を表示しています。
4.おまけ(参考)
⑩ 前項の「区分」が "B" の行を表示 のFILTER関数の第1引数の範囲を「金額」のみにすることで、区分Bの合計金額を計算することができます。これはSUMIF関数での計算と同じ結果となります。
⑪ 該当の個数(行数)を数えたい場合は、第1引数の金額の配列をISNUMBER関数で囲い、1を乗じることで計算できます。ISNUMBER関数は数値かどうかを判定する関数ですので、配列が数値であればTRUEが返ります。これに1を乗じることでFILTER関数の結果は{1;1}となり、これをSUMで集計すると個数となります。これはCOUNTIF関数での計算と同じ結果です。
【Excel】スピルで試算表データから貸借対照表(資産の部)を作成
1.処理の概要
Excelの関数(スピル)を使って、試算表データから下図のような貸借対照表(以下、BS)の資産の部を作成する例を説明します。
下図A4セルに数式を入力し、スピルさせることでA4以下のセルに貸借対照表を表示します。


前提条件等は以下の通りです。
・元になるデータは、試算表データ(円単位)と科目マスタの二つ。いずれも作成するブックのシートにセットする。
・試算表データの「前残」「残高」列が、それぞれBSの「前事業年度」「当事業年度」に対応する元の数値となる。
・科目マスタは試算表の科目とBSの科目等をひも付けるために使用する。
・試算表データは、会計システム等から期間を指定して出力すると毎回同じ体裁のデータを出力できる想定。
・最終的に試算表データの中身を変更すると、BSも自動的に変更される。
・便宜上、BSの負債の部及び純資産の部は考慮しない。
なお、今回説明する数式はあくまでひとつの例です。同じ結果を出すにしても色々な方法がありますし、Excelのバージョンによっても変わります。
私のExcelはMicrosoft365ですが、最新のGROUPBY関数などはまだ使えないため、今使える関数と自分の知識の中で可能な方法で書いていますのでご理解ください。
2.説明
①「BS」という新規シートに数式を入れていきます。
最終的に長い数式となりますので、LET関数を用いて中間計算を行いながら段階的に作成していきます。この後は、LET関数の中の名前(変数)ごとに説明します。

②以下、画像は基本的にA3セルに入力した数式を画像右側(下図の場合はF列)に表示して説明します。
LET関数の名前(変数)には頭に _ を付けています。名前自体は適当なものをつけています。(説明の中で変数単体は「」書きで表記)
下図の場合、「_データ」という名前にFILTER関数を使った計算を値として入れ、最後の計算で同じ名前「_データ」を入れることで「_データ」の結果をA3セル以下に出力しています。(以降同様)
以下説明をしていきます。
「_データ」は、使用する試算表データを入れます。単純に「試算表_d」シートを参照して、「試算表_d!A3:D38」とデータの範囲を入力してもよいのですが、データが増減した場合を考慮して、FILTER関数の第一引数で「試算表_d」シートのA~D列すべてを参照してから第二引数でB列が0以外(空白でない)の行に絞り込んでいます。A列ではなくB列を指定しているのは、A1セルに「試算表データ」と文字列が入力されており、A列を指定すると1行目が表示対象になってしまうためです。
③次の「_マスタ」も先ほどと同様の処理で、「BS科目_m」シートから科目マスタのデータを取り出していますが、こちらは後続の処理を考慮してDROP関数で1行目の見出し行を除いたデータ部分のみを指定しています。
この後は、このマスタをベースに試算表データの各残高を当てはめていく処理を行っていきます。
下図ではわかりやすいように1行目に元データの列番号、2行目に見出し名を入力しています。
④次の「_tj」では、まずCHOOSECOLS関数で先ほどの_マスタのうち、集計に使用する4,5,6,7列の4列に絞り込んでいます。
さらにBYROW関数、TEXTJOIN関数で、4列の配列を各行毎に”_”で連結します。この”_”は別の値でも構いませんが、後続処理で配列を再分割する際の区切り記号として使いますので、連結する4列の中で使われていない文字列にする必要があります。
⑤次の「_val」は、「_マスタ」の勘定コードと一致する「_データ」の前残と残高を抜き出します。
VLOOKUPやXLOOKUP関数でも処理できますが、今回は複数行(前残、残高)を配列からまとめて取る方法として、INDEX関数とXMATCH関数を使います。
INDEX関数の第一引数の配列には、「_データ」を設定します。第二引数の行番号には、「_マスタ」の勘定コードの行番号に対応する「_データ」の勘定コードの行番号を取得したいので、XMATCH関数を使います。XMATCH関数の第一引数の検索値には「_マスタ」の1列目(勘定コード)、第二引数の検索範囲には「_データ」の1列目(勘定コード)を設定します。それぞれ配列の1列目を取るためにTAKE関数を使っていますが、ここはCHOOSECOLS関数に置き換えても問題ありません。
INDEX関数の第三引数の列番号は、「_データ」の3列目(前残)と4列目(残高)を取りたいので、配列形式で {3,4} と入力します。
「_マスタ」の中の勘定コード1211、1405,2200は、マスタとして登録はあるものの実際に発生していない(「_データ」の中にない)科目です。前述のXMATCH関数で一致しないものは #N/A が返りますので、IFNA関数を使って一致しない場合は 0 を返すようにします。
数式の最後で、「_マスタ」の末尾の列(金額区分)を乗じています。この「金額区分」は各勘定をBSでプラス表示するかマイナス表示するかを区分するものです。具体的に言うと、このマスタの中で「金額区分」に -1 が入っているのは「貸倒引当金」のみで、それ以外は 1 が入っています。
「貸倒引当金」は負債科目ではありますが、BS上は資産の評価として資産の部でマイナス表示します。試算表上は負債科目の残高としてプラス金額となっていますが、BS上でマイナス表示するためにここで調整しています。 、
、
⑥REDUCE関数を使って繰り返し処理を行い、UNIQUE(_tj) に対応する集計値を計算します。少し複雑な計算をしていますので、次の画像で詳細の説明をしています。※UNIQUE(_tj)は「_tj」の値を一意にした配列
このREDUCE関数を使った計算はこの後も何度か登場します。


⑦「_ts 」もREDUCE関数+VSTACK関数を使った繰り返し処理です。
「_tj 」では「_マスタ」の4列を行ごとに"_”で1つの値に繋げました。今後は逆にそれを一意にした配列 UNIQUE(tj) をTEXTSPLIT関数で”_”を区切り記号として分割することで、4列の配列に戻します。
⑧(参考)
前頁で仮に、REDUCE関数を使わずに直接配列に対して、TEXTSPLIT(UNIQUE(_tj),"_") とすると、1列目のみが戻り値となってしまいます。他のSPLIT系関数やXLOOKUP関数でも同じ結果となります。
これは仕様の問題のようです。ですので、REDUCE関数で配列の値を1つずつ計算した結果をVSTACK関数でつなぐ処理を行っています。
⑨次の「_m」は「_total」の金額をROUND関数で百万円単位にしたものです。
今回は貸借対照表の資産の部のみの作成ですので単純な計算にしていますが、負債・純資産の金額まで考慮して表示単位を円から変更する場合は、貸借を一致させるため端数の調整を別途考える必要があります。
⑩前頁まではBSに表示する各科目と金額を作りました。
ここからはBSの形にするために見出し、各科目と金額、各合計金額を一つにする処理を行います。
準備した部品を組み立てるイメージです。
「_fx」は直接の計算式ではなくLET関数の中でLAMBDA関数を使ったオリジナルの関数です。次の「_cal」の中で「_fx」という関数名を使用する形をとっています。「_fx」の中身を説明します。
LAMBDA関数に設定する引数は一つで、x としています。このxには科目マスタの分類2(「_ts」の2列目)を入れる想定です。
計算では、LET関数で処理を分けています。
「_fill」・・FILTER関数で「_ts」と「_m」を結合したものを出力する配列とし、「_ts」の2列目=x、さらに「_m」の2列が0でない行に絞り込み。
「_total2」・・BYCOL関数で_fillの金額2列の合計を計算
「_sort」・・SORTBY関数で「_fill」の並び替えをします。基準配列は「_fill」の4列目でこれが分類2ごとの「表示順」となります。
「_cc」・・「_sort」をもとにBSに表示する列のみを選択しますが、この際にBS科目名の頭に表示位置調整用の空白(" ")を追加します。
「_hs」・・BSに表示する合計行を設定します。BS科目名と同じ列の並びに見出しを入れるので、空白(" ")& x(分類2)&"合計”を1列目、合計金額の「_total2」が2列目になるようにHSTACK関数を設定します。
最後のLET関数の計算は、VSTACK関数で「_cc」と「_hs」を縦につなぎます。
「_cal 」でREDUCE関数を使って繰り返し処理します。REDUCEの配列には「_ts」の2列目をUNIQUE関数で囲ったものを設定します。
少しわかりにくいですが、REDUCEの中のLAMBDAに変数accとzを設定し、VSTACK(acc,z,_fx(z)) で繰り返し処理した結果を縦につなぎます。ポイントはVSTACK(acc,の後にzを入れるところです。このzがBSの各勘定名の頭に入る見出し名となります。
これによって、分類名、勘定科目、分類の合計が各分類ごとに縦に並ぶ形になります。
⑪ 後は、BSの不足している部分を追加していきます。
「_固定計」、「_資産計」、「_vs」 は続けて説明します。
「_固定計 」は固定資産の合計行です。BYCOL関数を使って「_ts 」の1列目が固定資産の行の合計を計算します。
「_資産計 」は資産の部の合計です。ここではBYCOL関数で_mの合計を出しています。
「_vs 」はVSTACK関数を使って、前段で作成した「_cal 」と「_固定計」、「_資産計」を縦につなぎます。
ここまででBSの形にはなりましたが、先頭行に”資産の部”の見出しを、12行目の”流動資産合計”と13行目の”有形固定資産”の間に”固定資産”の見出しを入れる必要がありますので、次頁で説明します。
⑫「_addr 」の中でLET関数を使って”資産の部”と”固定資産”の行を追加する式を書いています。
「_見出し列」 ・・ 「_vs」の1列目を抜き出しています。
「_有形r 」 ・・ XMATCH関数を使って、「_見出し列 」の中の”有形固定資産”の位置を取得します。(”有形固定資産”の位置がわかれば、配列の途中に行を挿入することが可能)
戻り値は 11 です("有形固定資産"は配列の先頭から11番目に出現)。
最後の計算で、VSTACK、TAKE、DROP関数を使って”資産の部”、”固定資産”の行を挿入します。
まず、先頭に”資産の部”の見出し行をセットします。({"資産の部","",""}→後ろの空白2つは入れなければN/A#となるので、後でIFNA関数を使って取り除くことでも可)
次に、TAKE関数で「_vs 」の先頭から10行を取り出し、”固定資産”の見出し行をセット、最後にDROP関数で「_vs 」の先頭から10行を削除した配列を置き、これらをVSTACK関数で縦につなぎます。
⑬1~3行目は手入力しています。
B,C列の合計行の罫線は、B4:C40の範囲を対象に(行の増加を考慮して40行目まで)条件付き書式を設定しました。
これで完成です。
【Excel】ドロップダウンリストの設定セルを明示するため、当該セルにコメントを表示
(1) やりたいこと
人に入力してもらうためのExcelフォーマットにドロップダウンリストを設定してリストから選択してもらいたい場合の話です。
下図の例はD4セルにデータの入力規則のリストを設定しています。
ただ、その項目(セル)にドロップダウンリストが設定されているかどうかは、何も書いていない場合そのセルを選択しないとわかりません。
そこで、リストから選択してもらうことを明示するためにメモ等で説明を加えたりします。
例えば、下図のようにセルにメモ(コメント)をいれてみたり、
データの入力規則の入力時メッセージでセルを選択時に表示されるようにしたり、
隣のセルに説明書きを入れたり、まあこれでもよいのですが、、
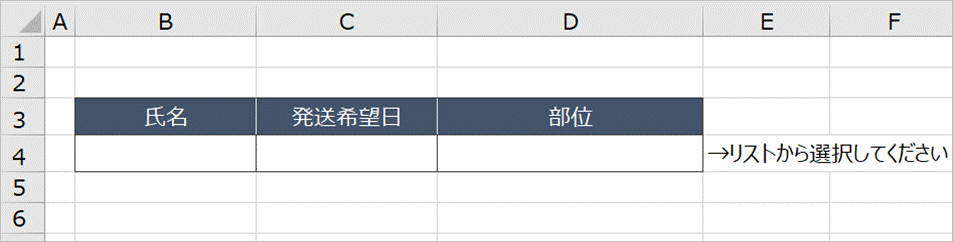
今回やりたいのは、下図のように入力対象のセルにコメントを表示させて、
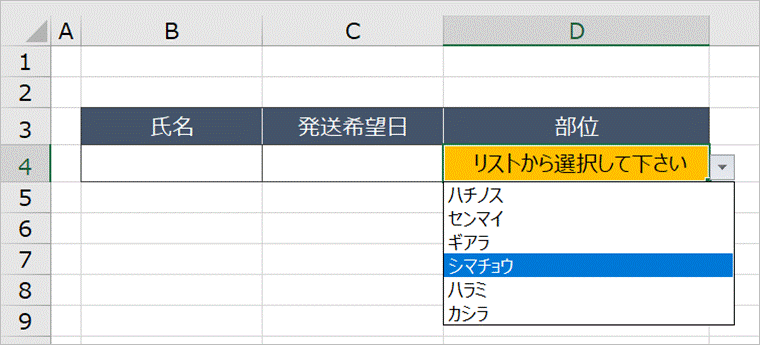
リストから選択した後は元のコメントを消すというものです(当然、リストの項目のひとつにコメントいれるというのはなし)。今回の表のようにシンプルなものであればどの方法でもよいのですが、もっとごちゃごちゃしたフォームやリスト選択の箇所が多いものの場合、メモや別セルへの入力だと見にくくなると思い、直接セルに表示させるのがよいかなと思いました。次項からやり方を説明します。
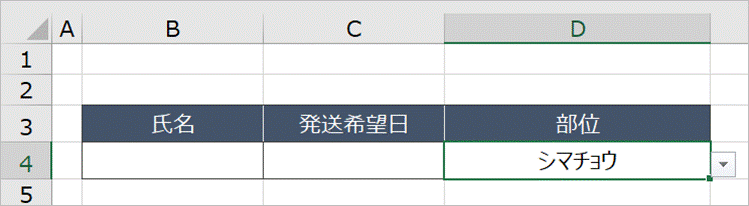
(2) 方法
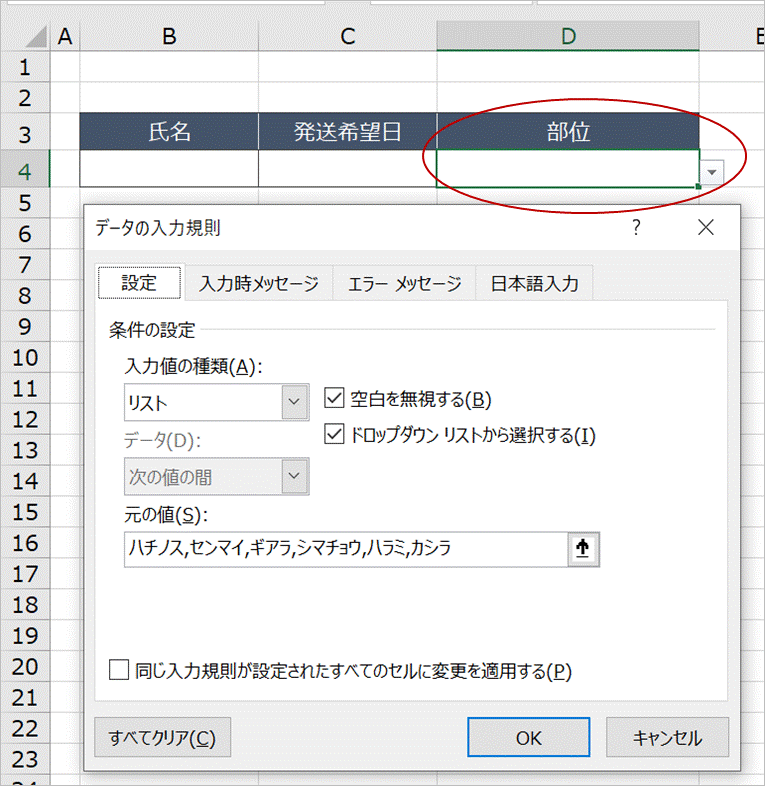
まず、D4セルにはデータの入力規則からリストの設定がされている状態からスタートします。
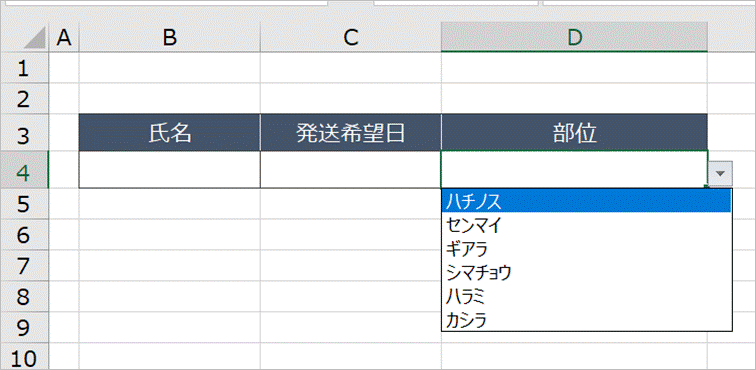
条件付き書式ルールの管理を開き(Alt+O,D)、新規ルールをクリックします。
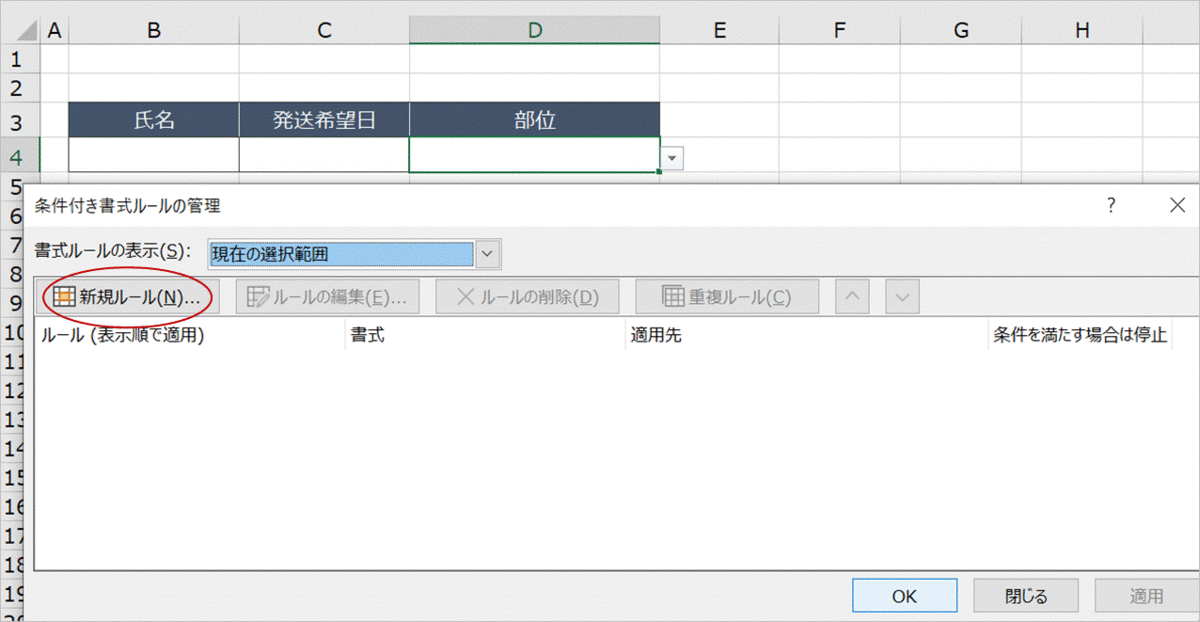
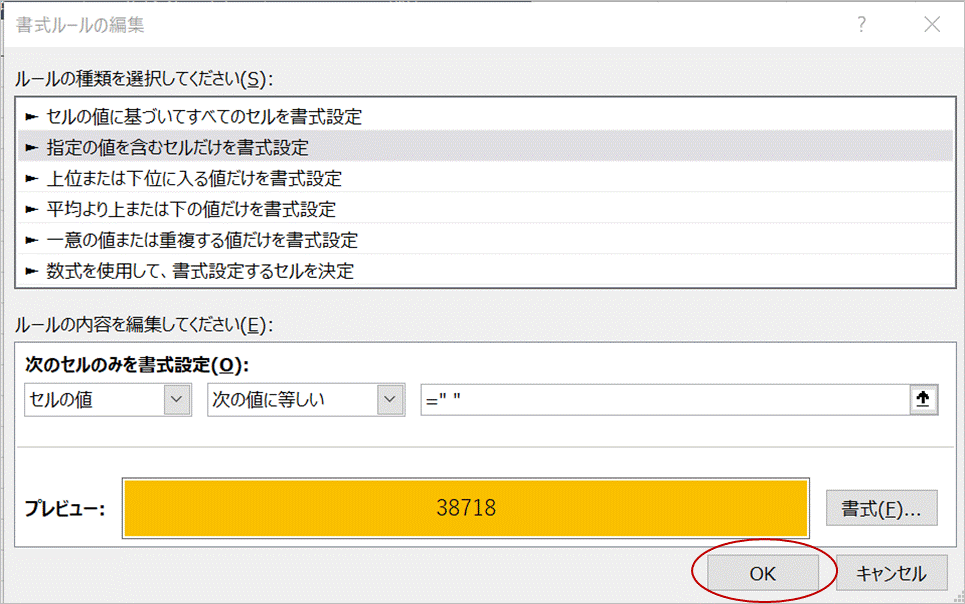
「指定した値を含むセルだけを書式設定」を選択し、下図の通りルールを設定します。
数式のところは、=" " (半角スペース)です。次に「書式」をクリックします。
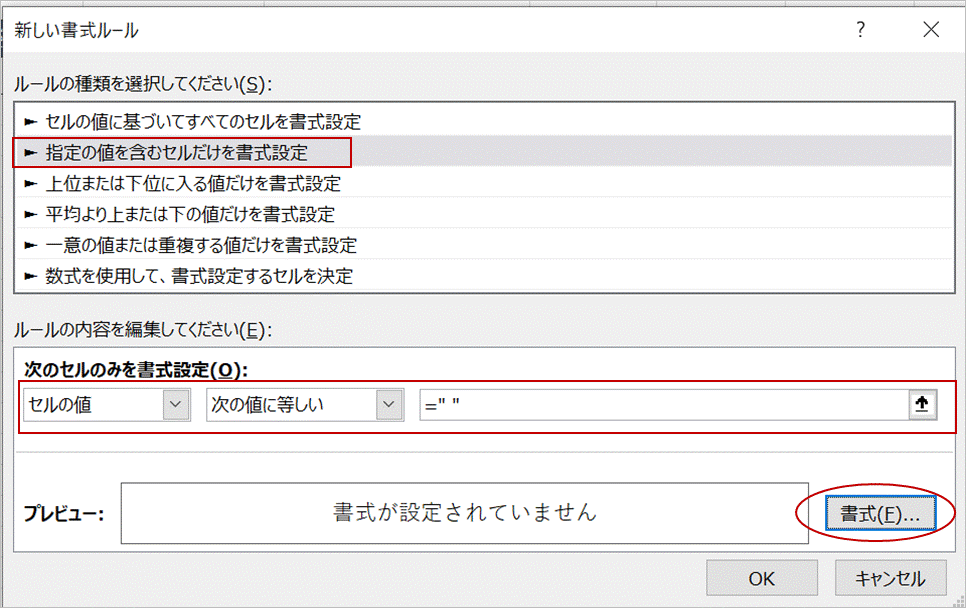
表示形式タブでユーザー定義を選択し、種類に @ に続けて表示したいコメントを入力します。入力される文字列(半角スペース)に続けて@に続く文字列が表示されるようにするためです。
その他に設定したい書式を設定します。
OKをクリックします。
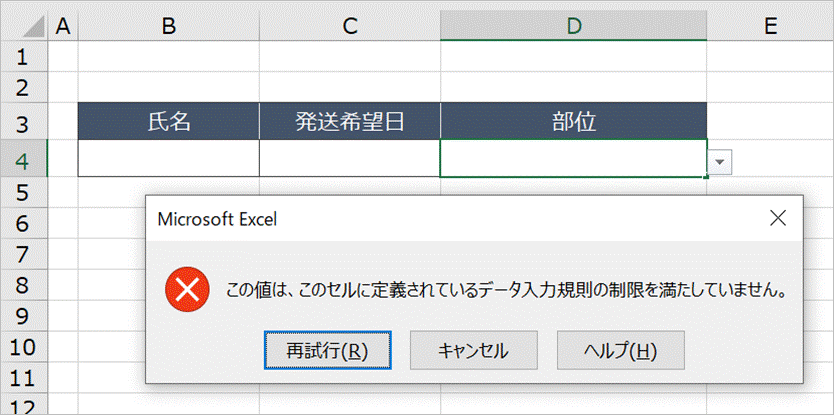
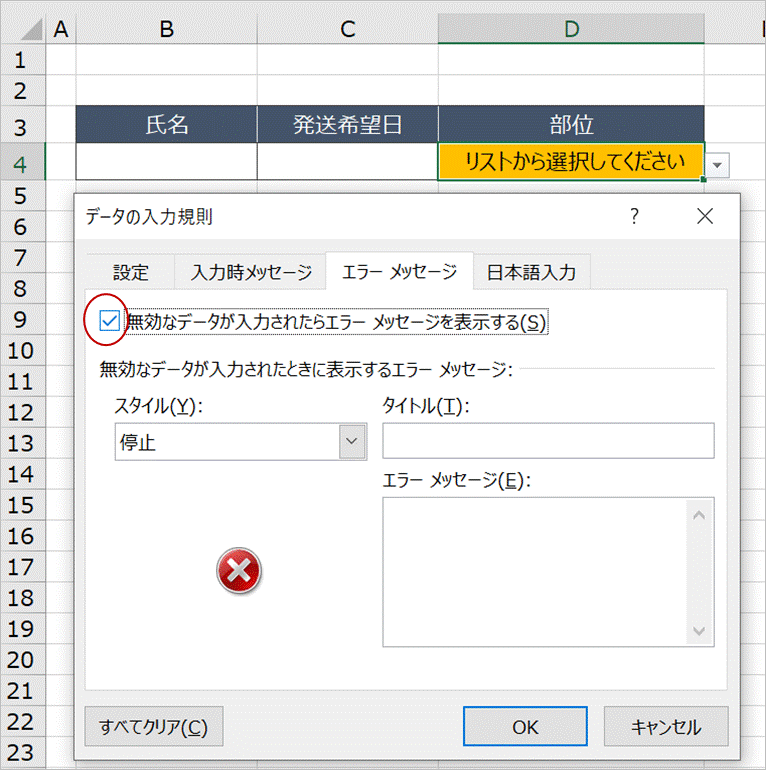
次からがポイントです。D4セルに半角スペースを入力しようとするとデータの入力規則の設定により下図のようにエラーとなります。
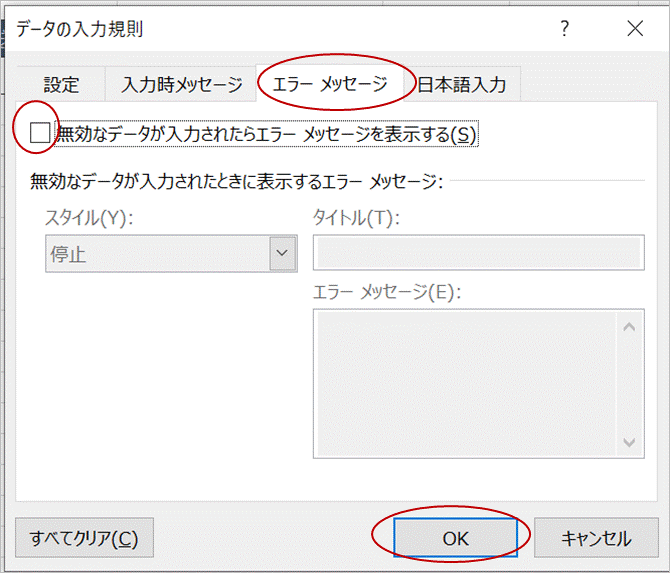
これを回避するため、データの入力規則を開き(Alt+D、L)、エラーメッセージタブの「無効なデータが入力されたらエラーメッセージを表示する」のチェックを外します。
これでD4セルに直接入力ができるようになりますので、半角スペースを入力すると条件付き書式の設定により、下図の通りの表示となります。ただ、プルダウンリスト以外の入力を許可するのであればこれでよいのですが、そうでない場合はこの状態から先ほどの「無効なデータが入力されたらエラーメッセージを表示する」にチェックを入れる必要があります。

これで完成です。
【Excel】ピボットテーブルで挿入したスライサーで選択中の項目を取得する。
(1) やりたいこと
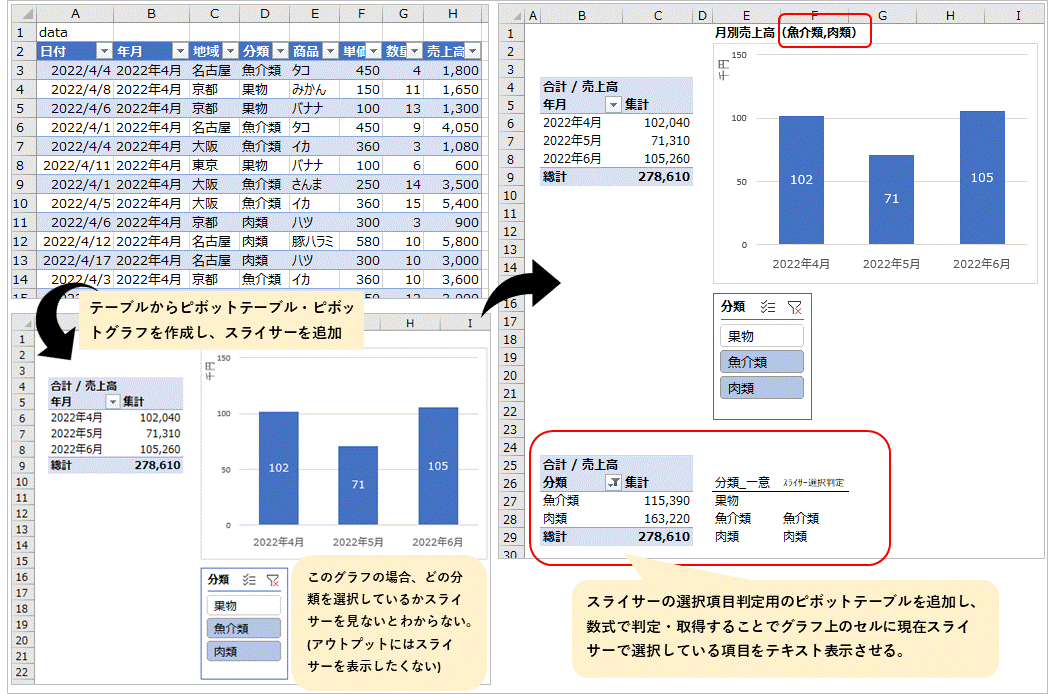
データテーブルからピボットテーブルで集計し、ピボットグラフを作成。これにスライサーを設定して項目の絞込みと連動するグラフを作る時の話です。
スライサーでどの項目を選択したかはスライサーのボタンの色を見ればわかりますが、最終的なアウトプットにスライサー自体を表示したくない場合、現在スライサーで選択している項目を取得してセルやテキストボックスできればよいと思い考えてみました。
下図が概要をまとめたものです。
(2) 事前準備
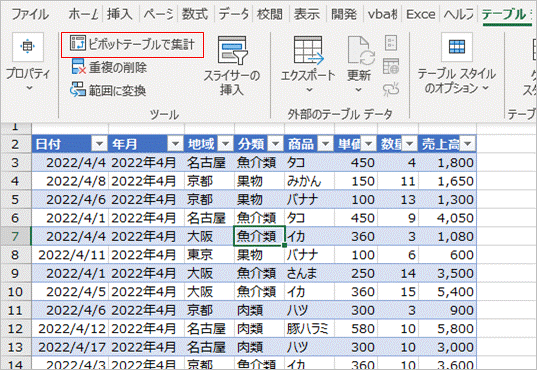
まず、(データがテーブルの場合)テーブルデザインタブの中の「ピボットテーブルで集計」からピボットテーブルを作成します。
データの列項目は複数ありますが、今回は月別の売上高推移の棒グラフを作りたいので、ピボットテーブルの行に「年月」、値に「売上高」をセットします。
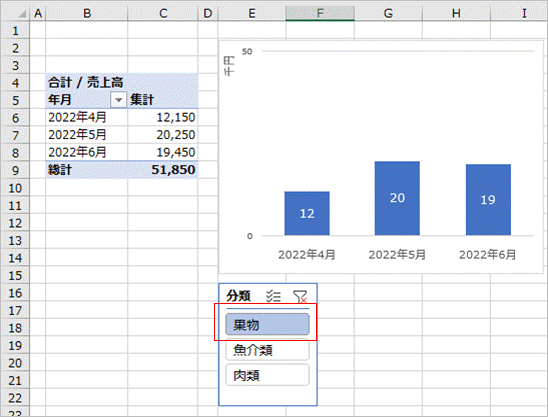
ピボットグラフとスライサーを追加した状態(説明は省略します)が下図となります。スライサーは分類としました。
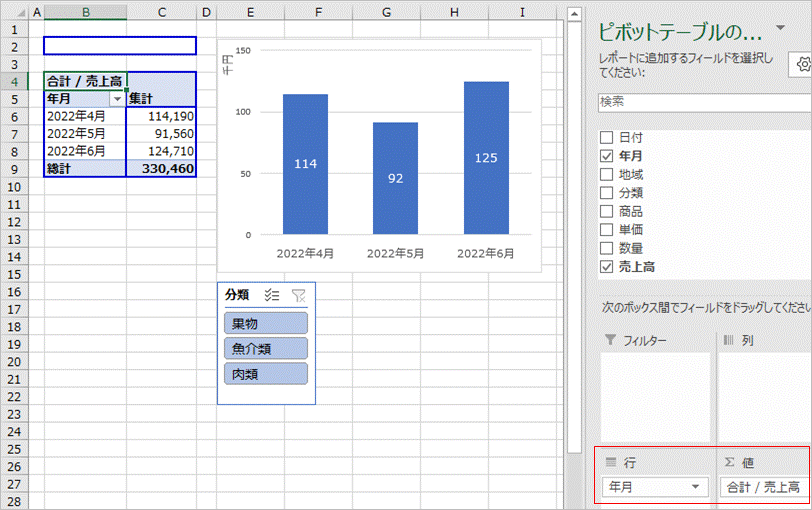
この状態で例えばスライサーの「果物」を選択するとピボットテーブル、グラフともに連動して「果物」だけの数値に絞り込まれます。
(3) スライサー選択項目の取得方法
(以下、説明用にすべて一つのシートで進めていきますが、実務ではグラフ・スライサーとピボットテーブル、数式は別シートに分けるのが無難だと思います。)
まず、元データからピボットテーブルを追加します。行にはスライサーと同じ項目「分類」を、値は「売上高」をセットします。(値はなんでも構いません)
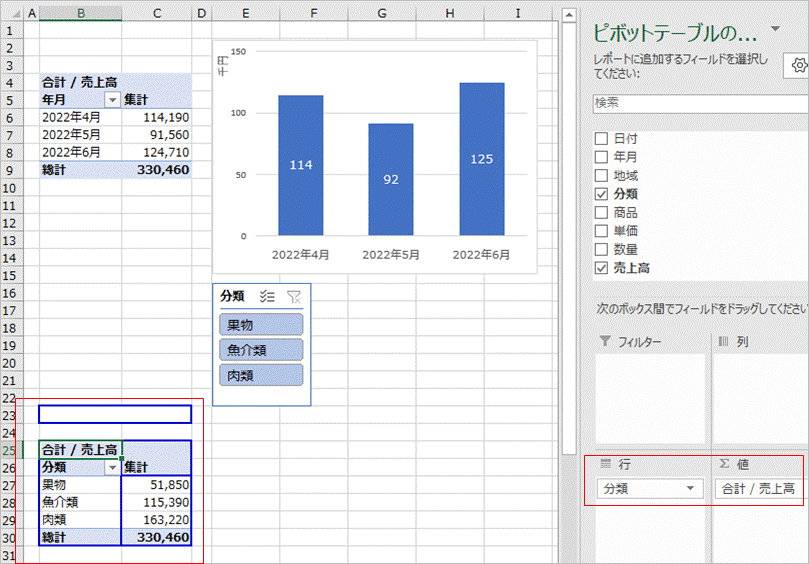
スライサーを選択した状態で右クリックし「レポートの接続」をクリックします。
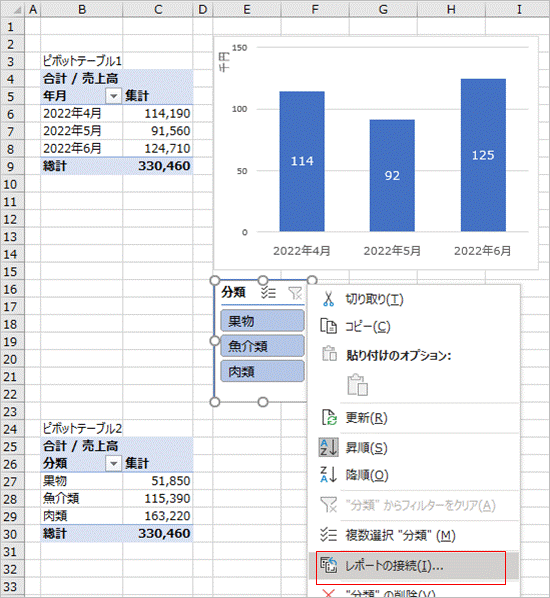
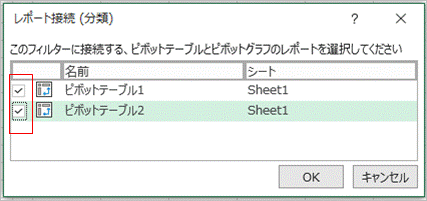
二つのピボットテーブルの左端のチェックボックスを選択してOKをクリックします。
これで二つのピボットテーブルが接続されます。
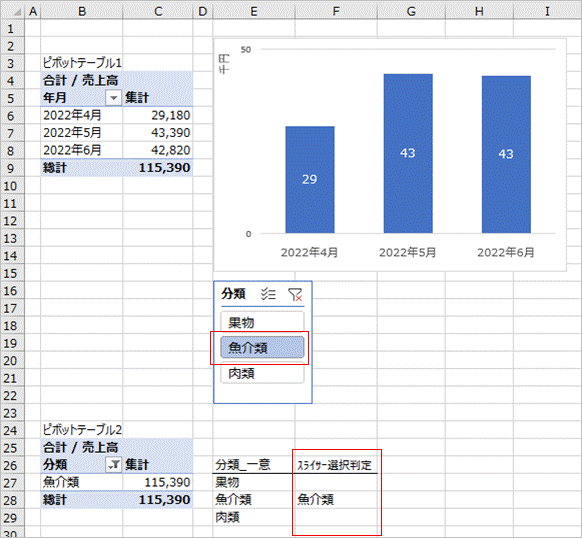
試しにスライサーで「果物」と「肉類」を選択すると、下のピボットテーブル2も連動して果物と肉類に絞り込まれます。

ここからセルに数式を入れていきます。E26、F26の「分類_一意」「スライサー選択判定」は手入力した見出しです。
まず、E27セルに元データの分類が一意となるように次の数式を入力します。
=SORT(UNIQUE(data[分類]))
UNIQUE関数でdata(テーブル名)の分類列の一意の値を取得した結果をSORT関数で降順に並び替えています。
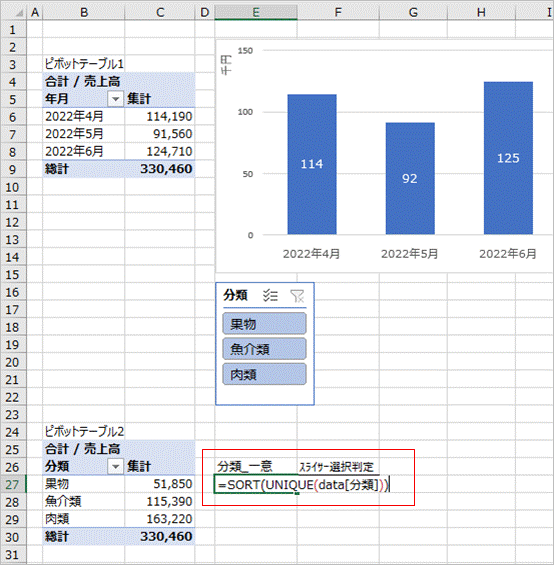
下図の通り表示されました。スピルされますのでテーブルに新しい分類が追加された場合も自動的にこの数式の結果に追加されます。
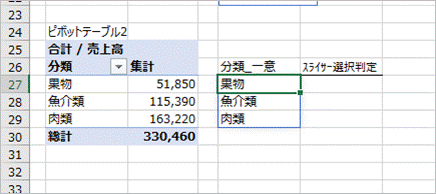
次にとなりのF27セルにスライサー選択判定用の数式を入力します。
=IF(ISERROR(GETPIVOTDATA("売上高",$B$25,"分類",E27)),"",E27)
GETPIVOTDATA関数でピボットテーブル2の分類にE27の値がなければエラーとなるので、IFとISERROR関数を使いエラーの場合はブランクとし、値がある場合はE27の値を返すようにします。
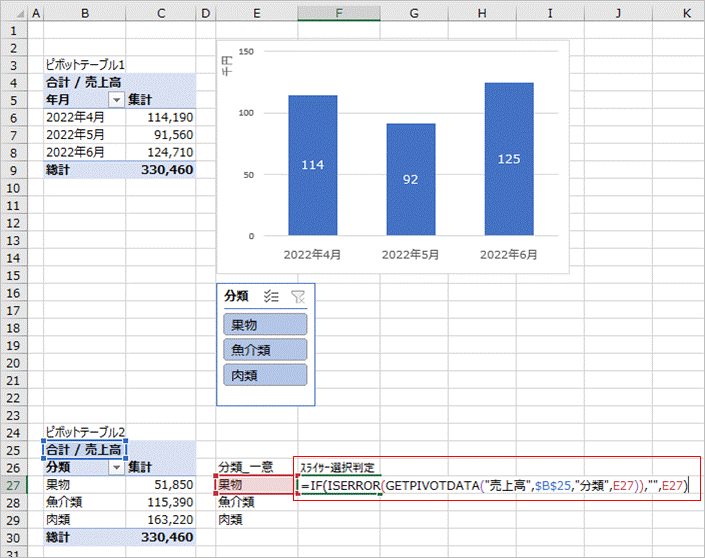
果物は選択されているので「果物」が返ります。
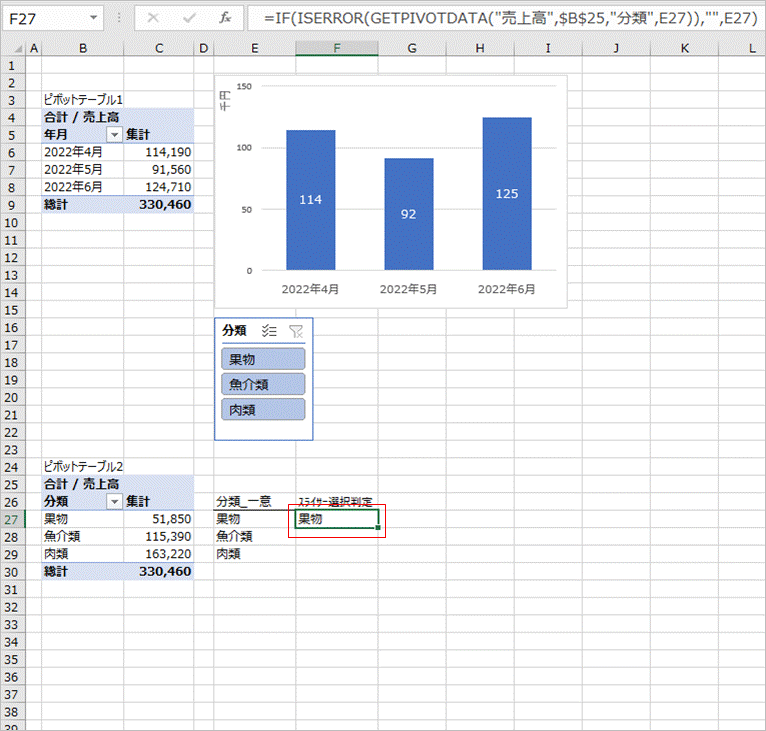
F27の数式を下にコピーします。分類数は3つですが、データに新規分類が追加されても対応するように適当なところまでコピーしています。(が、ここはもっとよい方法があるのではないかと・・納得できていません)
これでスライサーで選択中の項目を取得することができました。
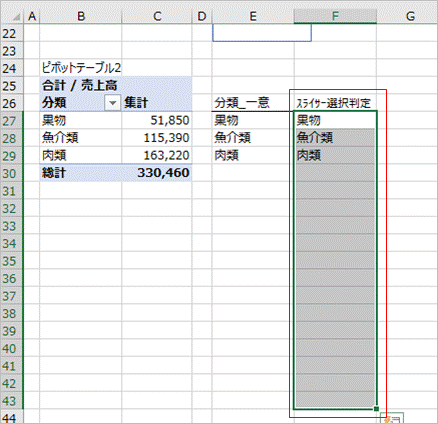
試しに「魚介類」に絞り込むと下図の通り正しく表示されました。
最後に、取得した判定結果を一つのセルに表示するための数式をE1セルに入れてみます。
=TEXTJOIN(",",TRUE,INDIRECT("F27:F"&26+COUNTA(E27#)))
やりたいことはF27~F29に表示された文字列をTEXTJOIN関数で「,」で区切って繋げたいだけなのですが、新規分類が発生した場合にセル参照範囲が変わってしまうので、COUNTA関数でE27以下に表示された分類数を数え、INDIRECT関数でF列の参照に変換しています。(OFFSET関数等を使って別の書き方ができるかもしれません)
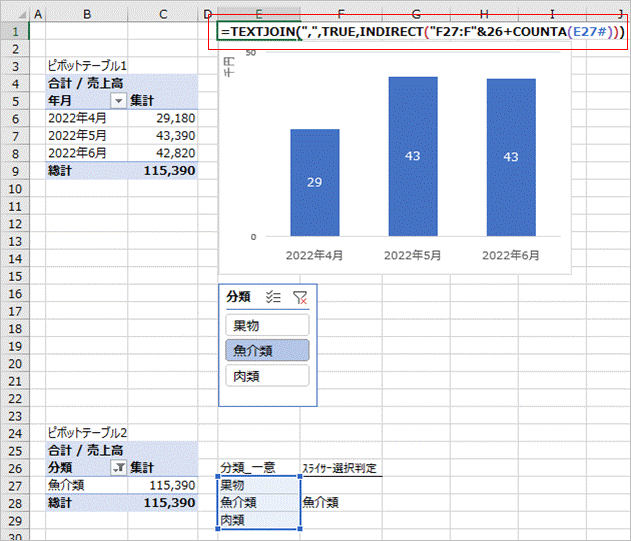
数式の結果がE1セルに表示されました。

複数の項目を選択すると下図のようになります。

あとは、先ほどの数式にタイトルなど任意のテキストを追加します。
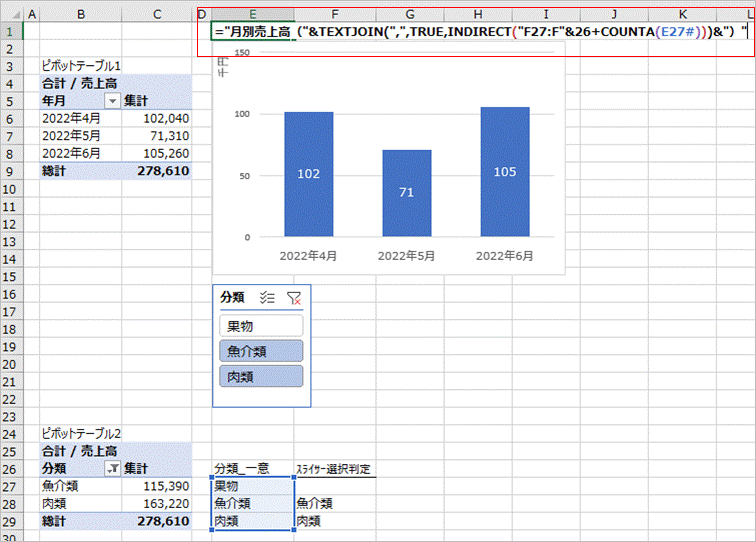
下図のように表示できます。

(4) 最後に
今回はひとつのスライサー項目のみとしましたが、複数のスライサーの項目を取得する場合はもうひと手間必要です。
試行錯誤しながら考えましたが、実はもっと簡単にピボットテーブルのスライサーの選択項目を取得する方法があるかもしれません。
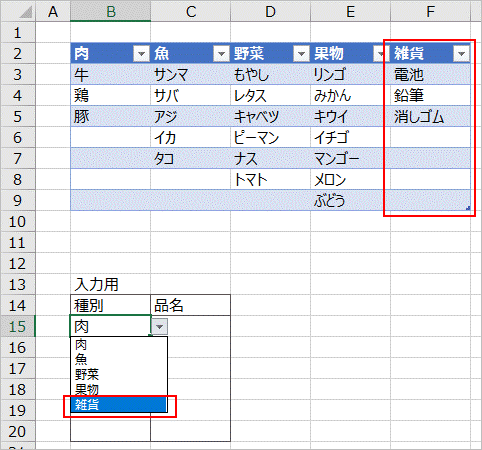
【Excel】2段階ドロップダウンリストの設定
2段階のドロップダウンリストの設定方法について説明します。様々なやり方があると思いますが、個人的には今回紹介する方法が一番スッキリしました。
(1) やりたいこと
下図に記載の通り、ドロップダウンリスト用のリストを作成し、一つ目のドロップダウンリストから選択したものに対応して、二つ目のドロップダウンリストの選択項目が変わるようにします。
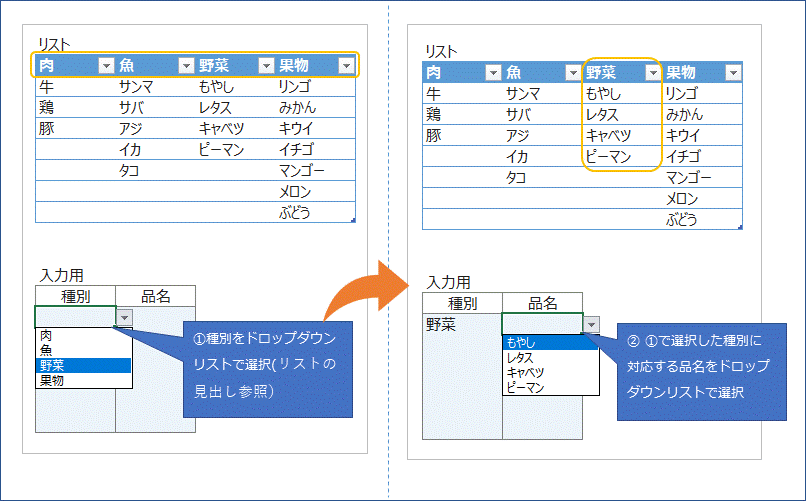
(2) 方法
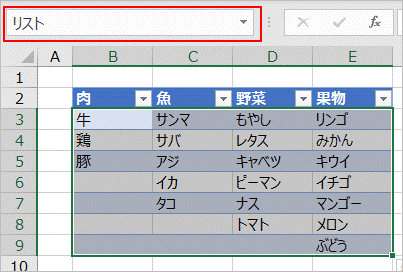
まず、適当なリストをセルに入力します。

作成したリストをテーブルにします。

テーブル名はデフォルトで「テーブル1」とつきますが、今回は「リスト」という名称に変更しました。
入力用のセルに「データの入力規則」でドロップダウンリストを設定していきます。
通常は先に作成したリストと入力用はシートを分けますが、今回は説明しやすいよう同じシートにしています。
まず、種別の項目から設定します。データの入力規則の設定タブに次の通り選択・入力します。
入力値の種類 : リスト
元の値 : =INDIRECT("リスト[#見出し]")

設定した種別のセルでリストの見出しに設定された項目が選択できるようになりました。

次に、品名のドロップダウンリストを設定します。
入力値の種類 : リスト
元の値 : =INDIRECT("リスト["&B15&"]")
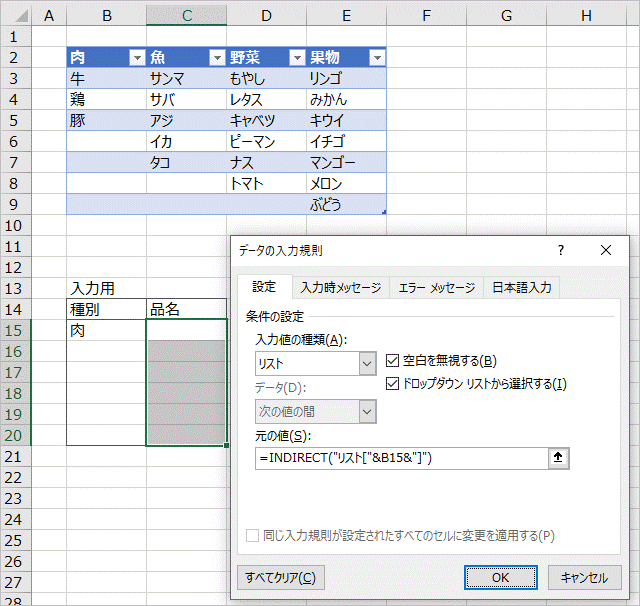
すると、ドロップダウンリストは設定できましたが、テーブルの空白行までドロップダウンリストに表示されてしまいました。これでも使うことはできますが、空白行が増えると使いにくくなりますので、先ほど入力規則の元の値に入力した数式を見直します。
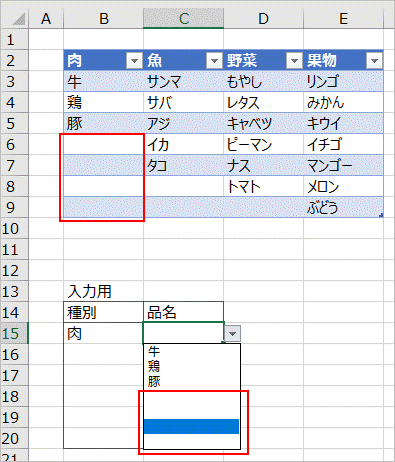
元の値を次の通り、修正します。
元の値:
=OFFSET(INDIRECT("リスト["&B15&"]"),0,0,COUNTA(INDIRECT("リスト["&B15&"]")))
つまり、OFFSET関数で各項目のデータ数分だけに絞込んであげます。

今度は空白行を除いた品名だけを選択できるようになりました。

以上で完成です。
(3) 補足:一つ目の項目が増えた場合
一つ目の項目が後から増えた場合も、下図の通りリストに追加で入力するとテーブルが拡張され、ドロップダウンリストの選択項目にも反映されます。